

At Alteeve, we take pride showing off the Anvil Intelligent Availability® platform at trade shows and universities. This article is the first of many in which we will offer answers to some of the common questions we receive at trade shows. As an Open Source availability solution, we are more than happy to share the logic behind our platform choices. Today, I’ll be writing about how we maximise storage resiliency without specialised equipment.
The Question:
Where’s your SAN?
How do you provide storage HA?
Why don’t you use blade servers?
Many High Availability platforms on the market today use expensive storage solutions to provide resiliency for their mission-critical data. These generally appear in the form of a SAN or some other network-attached storage. These devices offer a lot of data density in a single chassis, and usually come with a number of options such as hot-spare drives, and backup drive controllers to protect against failure. When looked at in isolation, these kinds of solutions seem ideal. However, in a SAN-dependant setup, your backing storage becomes a pivotal component on which your availability depends.
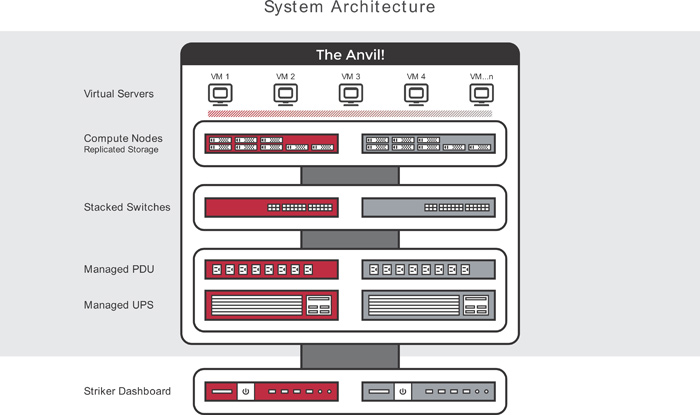
One of the elements the Anvil architecture brings to the High Availability field is its full-stack redundancy. From wall to compute, the architectural blueprint uses your choice of off-the-shelf, easily available equipment and blends it into a solid platform for your business and mission critical applications. Central to this is the idea that the platform must be able to survive not only equipment failure, but also recovery. Any component that requires services to be brought offline to maintenance becomes a liability for services that cannot bear downtime.
Let’s think through a couple examples:
SAN as backing storage
SANs have really stormed the enterprise market. They provide a robust platform and bulk storage. Unfortunately, unless a SAN is deployed in a stack with Intelligent Availability® in mind, they fail to overcome a few key sources of downtime.
First off, we need to consider the contents of a storage appliance. Does it have multiple drive controllers? Many devices do, but if yours doesn’t, that becomes a single point of failure. When your controller goes down, it takes all of your storage with it. Does your SAN have a single drive backplane? That also can be a single point of failure. More likely, however, is that one or more of these components may need to be replaced after failure, and that requires the full power-down of your backing storage and unavoidable downtime. In Intelligent Availability®, survival of recovery is just as important as surviving the failure.
The Intelligently Available® solution would be to have two SAN devices, mirroring each other. If one fails, it can be taken offline and maintenance them with zero downtime. These devices are expensive however, and the cost alone makes them difficult to justify as a ‘Fundamental’ component of our open source and accessible solution.
Hyperconverged Storage
Hyperconvergance means any number of things nowadays, but in availability it mostly refers to ‘stackable’ units that include compute and Directly-Attached Storage. Solutions of this kind are focused on the appliance provided, and rarely on the full context of your business. They are meant to provide agility to your compute and storage services, but uptime is a secondary feature. For absolutely critical services, it is paramount that the full server stack is considered, from power through networking, up to your compute and storage. Having a modular, extensible, hardware platform has many advantages, however catastrophic failure management is not one of them.
Developers of the Anvil! project firmly believe in Murphy’s Law. If it can break, it will break, and we must be prepared for that possibility. Distributed storage brings with it increased complexity, and a greater number of instances where a service stack can fail or hang. In simplifying the Anvil! stack to two nodes and having a robust full-stack blueprint, we eliminate guesswork. We eliminate complexity. Recovering from catastrophic failures becomes easily automated. Once we have accepted the inevitability of hardware and software failure, it is easy to see that a reduction in complexity directly correlates to better uptime.
Blade Servers
Blade chassis share concerns from both HC and SAN solutions. They too have a single backplane that all blade nodes depend upon. Many blade solutions also have compute and storage blades which are designed to allow for easy scalability, like in hyperconverged solutions. However, based on the Anvil! architecture blueprint, both of these shortcomings could be overcome through duplication, similar to the dual SAN option. If two blade backplanes were put in place, each with duplicated compute and storage nodes, the basic requirement of No Single Point of Failure would be overcome. Should a blade chassis fail, all services could be moved to the surviving chassis and the failed one taken offline and replaced.
Blade chassis have a much more fundamental reason for not being used in an Anvil! blueprint, however. Given that each blade in a set is a discrete computing component which interacts with it’s peers via the backplane and networking, any blade could be isolated by a networking, hardware, or software failure. When the cluster is not in communication with all nodes, the system must figure out which hardware should be in control of a service. Should the uncommunicative hardware be failed, we could safely assume that it won’t try to write data to a service it isn’t in control of. However, should that hardware still be in operation but isolated – a split-brain situation -, or frozen and unaware that it’s storage priority has been lost, it could attempt to write bad information to storage. Once that is done, service is disrupted and recovery is far from trivial.
To overcome this in a two-node traditional setup, the Anvil! uses multiple methods of ‘fencing’ to ensure that a lost node is put into a known state. The first is to use the management port available on all enterprise-grade server hardware, often referred to as an IPMI interface. This interface is essentially a mini computer inside the chassis of the server which allows for basic operations such as power cycling and monitoring of the main server hardware. Most if not all blade hardware offers this. However, IPMI can, and has, failed. If it were our only method of being able to ensure failed or isolated hardware was turned off and not threatening cluster services, we would be in trouble should an error occur when IPMI is inaccessible.
To overcome this, the Anvil! also uses at least one more fencing method. Usually this comes in the form of two APC networked PDUs. These devices could be summarised as networked power bars. They allow us, should IPMI fail, to have a backup fencing method: We can tell the PDUs to pull power from the ports that the isolated node draws power from. Once power has been removed from the offending device we can be sure that it is now in a known state (off), and services are safe. We have yet to find a Blade chassis that allows for the power management of independent blades within the chassis without powering off the whole array. Should that be an option, we’d eagerly consider it!
Our Solution: Linbit’s DRBD

The Anvil! project relies upon the Distributed Replicated Block Device (DRBD) software, from Linbit. This is a fantastic open-source solution that helps us slim the Anvil! hardware blueprint to a minimum. In short, DRBD allows us to take on-node storage on both Anvil! nodes, and create a single mirrored storage pool. Through the use of a dedicated VLAN (bonded across two interfaces per node, for resiliency) and common enterprise-grade SAS drives, the Anvil! has a storage pool that exists on both nodes simultaneously, at per-write consistency. To put it otherwise: Your storage exists on both your servers at the same time, in real-time. This allows our users to choose their hardware vendor of choice, and lowers the initial cost of hardware. If one node fails or must be taken down for maintenance, the other persists with zero downtime. Recovery is just as simple, with a replacement node or part being replaced not requiring a full stack downtime.
The matter of highly-available storage is a complicated one. There are a large number of products with lofty claims, and each falls into a use-case that suits it well. When it comes to putting service delivery front and centre, it is vital that you consider the failings as well as the strengths of a solution, especially when you remember that an Intelligently Available platform is prepared to both survive unforeseen catastrophic failure and recover from them automatically with minimal interruption. Linbit’s DRBD was the only product we found that matched every need we had for our users’ most business and mission critical services.
We’ll be posting more common questions, keep an eye on this space!
-Alteever